16. 分析性能
分析性能
在以下情况下,我们讨论过的所有 TD 控制算法(Sarsa、Sarsamax、预期 Sarsa)都会收敛于最优动作值函数 q_(并生成最优策略 \pi_):(1)\epsilon 的值根据 GLIE 条件逐渐降低,以及 (2) 步长参数 \alpha 足够小。
这些算法之间的区别总结如下:
- Sarsa 和预期 Sarsa 都是异同策略 TD 控制算法。在这种情况下,我们会根据要评估和改进的相同(\epsilon 贪婪策略)策略选择动作。
- Sarsamax 是离线策略方法,我们会评估和改进(\epsilon 贪婪)策略,并根据另一个策略选择动作。
- 既定策略 TD 控制方法(例如预期 Sarsa 和 Sarsa)的在线效果比新策略 TD 控制方法(例如 Sarsamax)的要好。
- 预期 Sarsa 通常效果比 Sarsa 的要好。
如果你要了解详情,建议阅读该教科书(尤其是第 6.4-6.6 部分)的第 6 章节。
为了加深理解,你可以选择练习重现图 6.4(注意,这道练习是可选练习!)
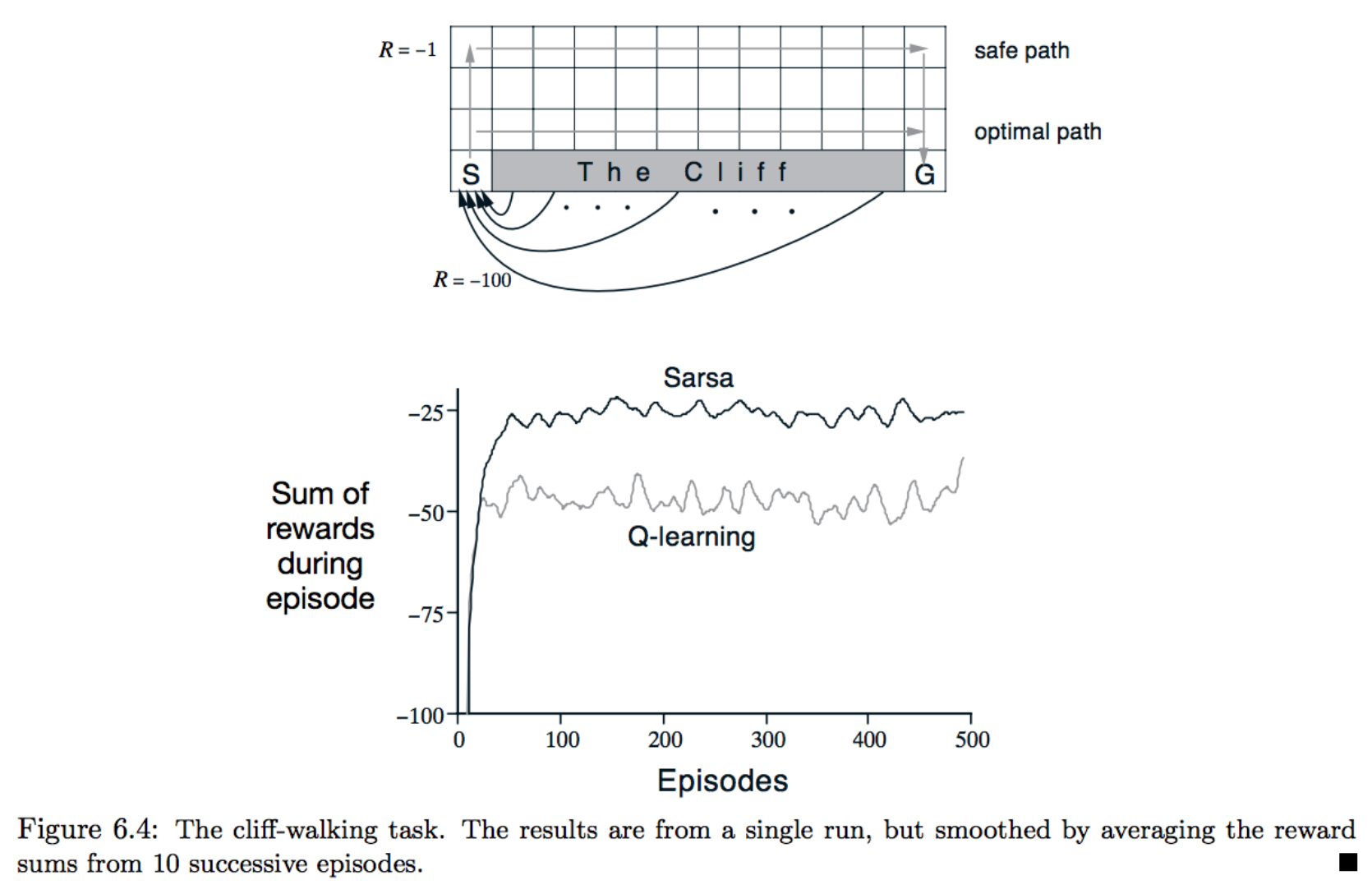
该图显示了 Sarsa 和 Q 学习在悬崖行走环境中的效果,常量 \epsilon = 0.1。正如在教科书中所描述的,在这种情况下,
- Q 学习的在线效果更差(智能体在每个阶段平均收集的奖励更少),但是能够学习最优策略,以及
- Sarsa 可以获得更好的在线效果,但是学到的是次最优“安全”策略。
你应该通过对现有代码稍加修改,就能够重现该图。